You can download the YouTube driving dataset following this link. The list of YouTube video can be download here.
Overview
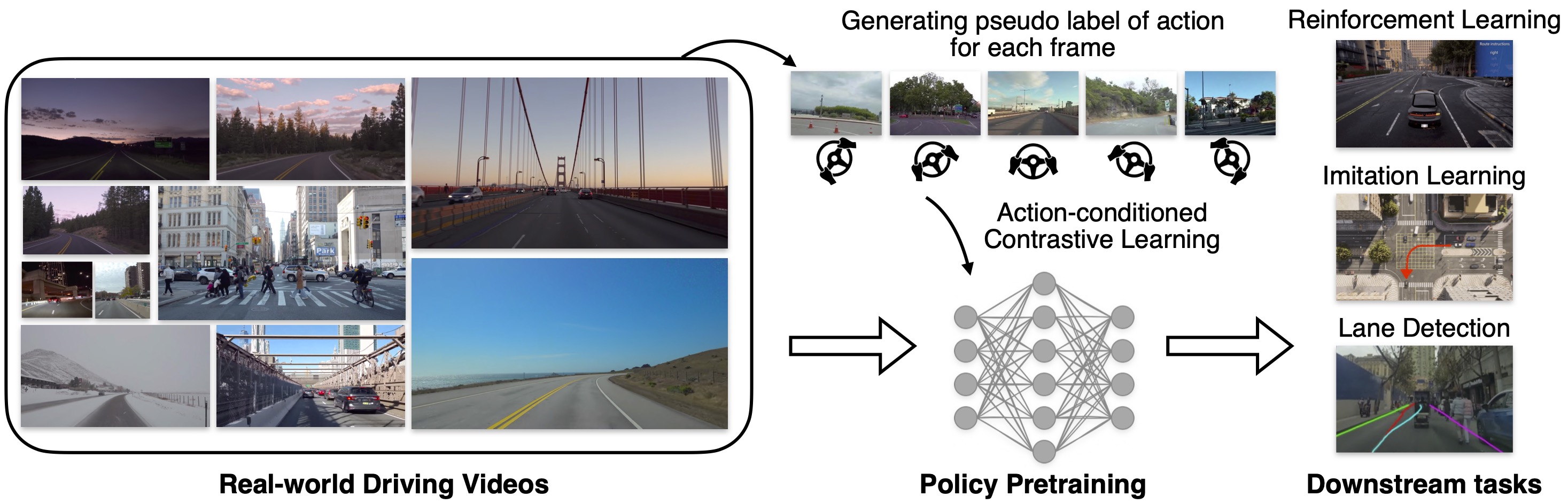
This work develops a novel action-conditioned policy pretraining method called ACO by learning from driving videos on the web. It learns to capture important features in the neural representation relevant to the decision-making and benefits various downstream tasks.
The method consists the following steps:
- We first collect a large corpus of driving videos with a wide range of weather conditions, from wet to sunny, from all across the world.
- We then train a inverse dynamics model with a small amount of labeled data and use it to generate action pseudo labels for each collected frame.
- We then develop a contrastive learning that incorporates action pseudo labels for representation learning.