Predictive Preference Learning from Human Interventions
NeurIPS 2025 Spotlight
Haoyuan Cai , Zhenghao Peng , Bolei Zhou
University of California, Los Angeles
Code | Poster | Demo Video | Paper
Summary
We develop a novel Predictive Preference Learning from Human Interventions (PPL) method.
- PPL predicts future failures with a lightweight trajectory predictor (runs at >1,000 fps on CPU) and helps human experts intervene promptly.
- PPL converts expert takeovers into contrastive preference labels applied over predicted future states.
In experiments on driving (MetaDrive) and manipulation (RoboSuite), under both real human participants and neural experts, PPL:
- Achieves 2x improvement in sample efficiency and reduces expert takeover cost compared to interactive imitation learning (IIL) baselines.
- Robust to trajectory-prediction noise and to imperfect experts, and consistently outperforms baselines under these realistic perturbations.
We also provide a theoretical analysis that:
- Upper bounds on the performance gap by the preference-dataset error, state-distribution shift, and training loss.
- Explains how to select the preference horizon \(L\) to balance these trade-offs.
Motivation
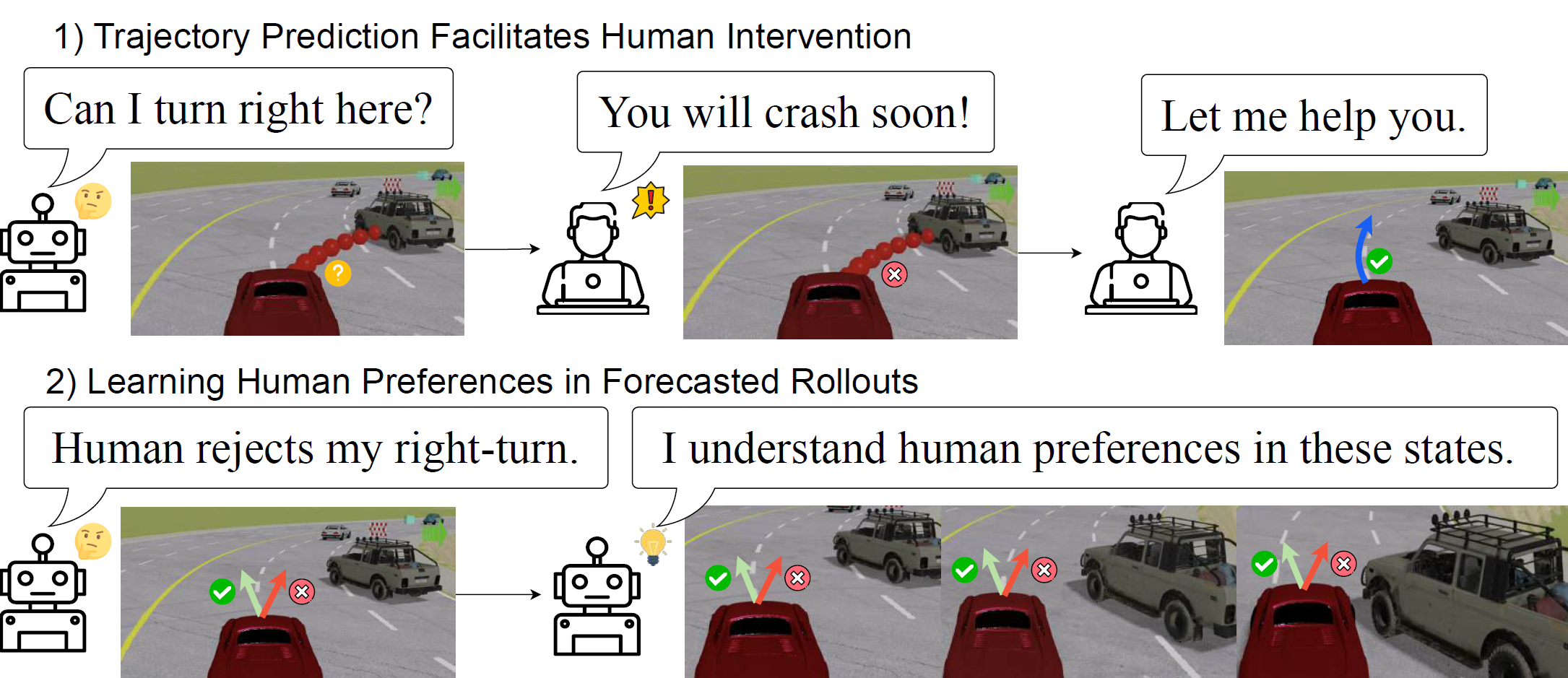
Existing IIL methods impose high cognitive burdens on humans as they require humans to constantly monitor the agent, anticipate future failures, and intervene in real time. Moreover, they do not fully utilize the agent’s predicted future behaviors, resulting in repeated human corrections and poor sample efficiency.
We propose Predictive Preference Learning (PPL) to reduce human workload and improve training efficiency. PPL combines a lightweight trajectory predictor and preference learning: the former helps humans proactively decide when to intervene, and the latter trains the agent to avoid future unsafe behaviors.
Predictive Preference Learning
As illustrated in the figure below, our method PPL operates through human-agent interaction and preference propagation over predicted trajectories.
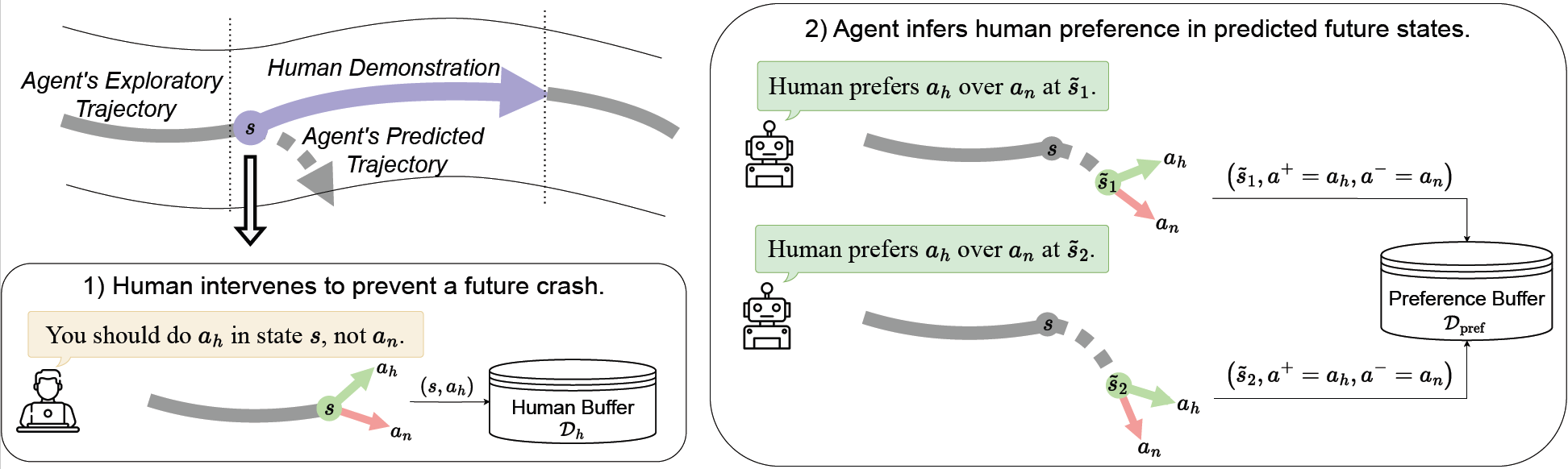
Agent’s exploratory trajectories: At each decision step, the agent proposes an action \(a_n\) from its novice policy \(\pi_n\), and a future rollout is predicted using a trajectory model \(f(s, a_n, H)\). This rollout \(\tau = (s, \tilde{s}_1, \dots, \tilde{s}_H)\) is visualized, and the agent proceeds autonomously unless the human anticipates failure.
Human Demonstrations: If the expert foresees risk (e.g., collisions), they intervene by suggesting corrective actions \(a_h \sim \pi_h(s)\), and we record \((s, a_h)\) into a human buffer \(\mathcal{D}_h\) for behavioral cloning. Importantly, we also treat this intervention as an implicit preference: the human prefers \(a_h\) over \(a_n\) not just at \(s\), but also at multiple predicted future states \(\tilde{s}_1, \dots, \tilde{s}_L\), forming tuples \((\tilde{s}_i, a^+ = a_h, a^- = a_n)\) stored in a preference buffer \(\mathcal{D}_\text{pref}\).
Learning with two complementary losses: We train the policy \(\pi_\theta\) with:
1) A behavioral cloning loss on expert demonstrations:
\(\mathcal{L}_{\text{BC}}(\pi_\theta) = -\mathbb{E}_{(s, a_h) \sim \mathcal{D}_h} \left[ \log \pi_\theta(a_h \mid s) \right]\).
2) A contrastive preference loss over predicted states:
\(\mathcal{L}_{\text{pref}}(\pi_\theta) = -\mathbb{E}_{(\tilde{s}, a^+, a^-) \sim \mathcal{D}_\text{pref}} \left[ \log \sigma \left( \beta \log \pi_\theta(a^+ \mid \tilde{s}) - \beta \log \pi_\theta(a^- \mid \tilde{s}) \right) \right]\).
This design allows the agent to propagate expert intent into imagined states before entering risky regions, enabling safer and more efficient policy learning with fewer interventions.
Experiment
Compared to the IIL baselines, our method PPL achieves superior learning efficiency in the following tasks:
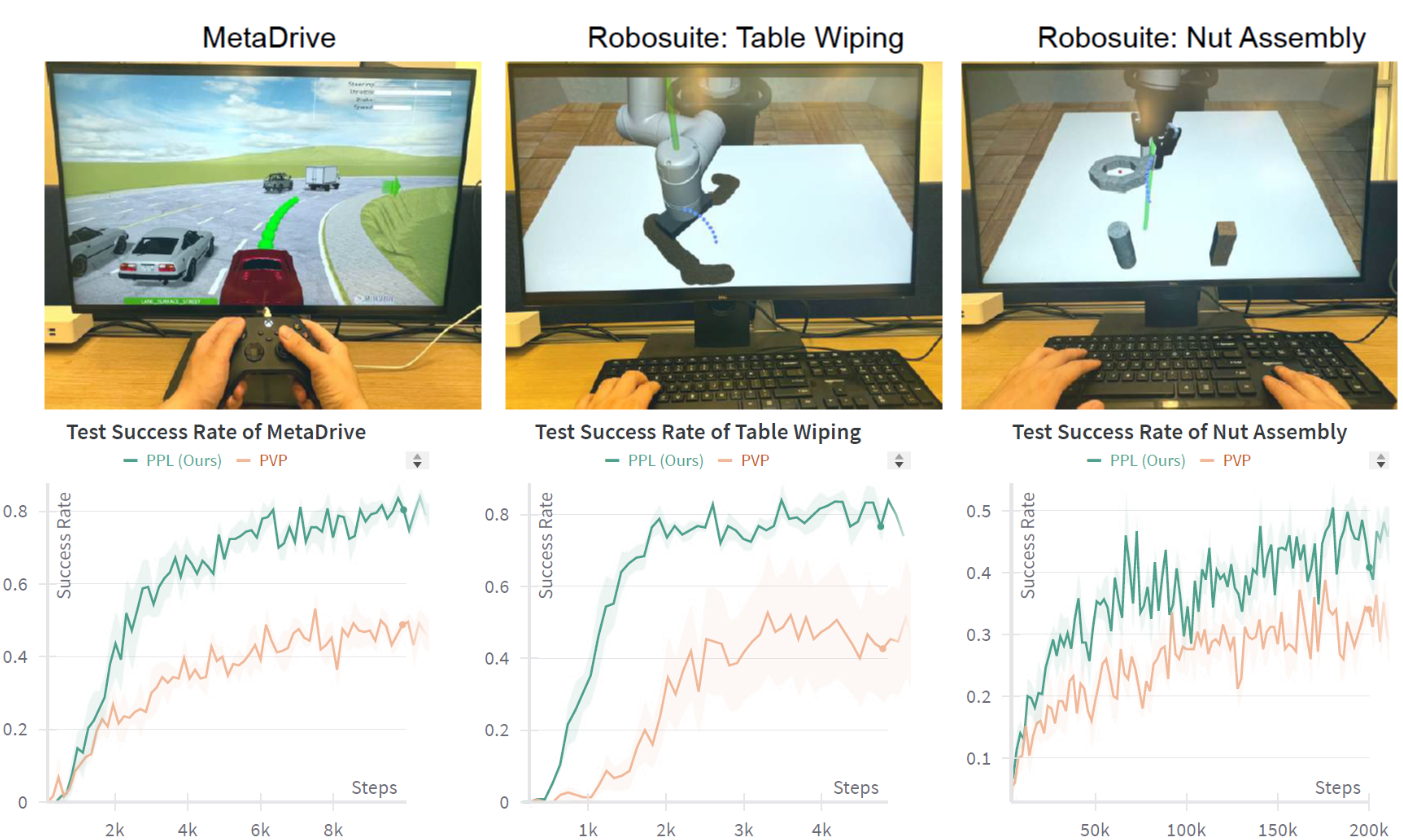
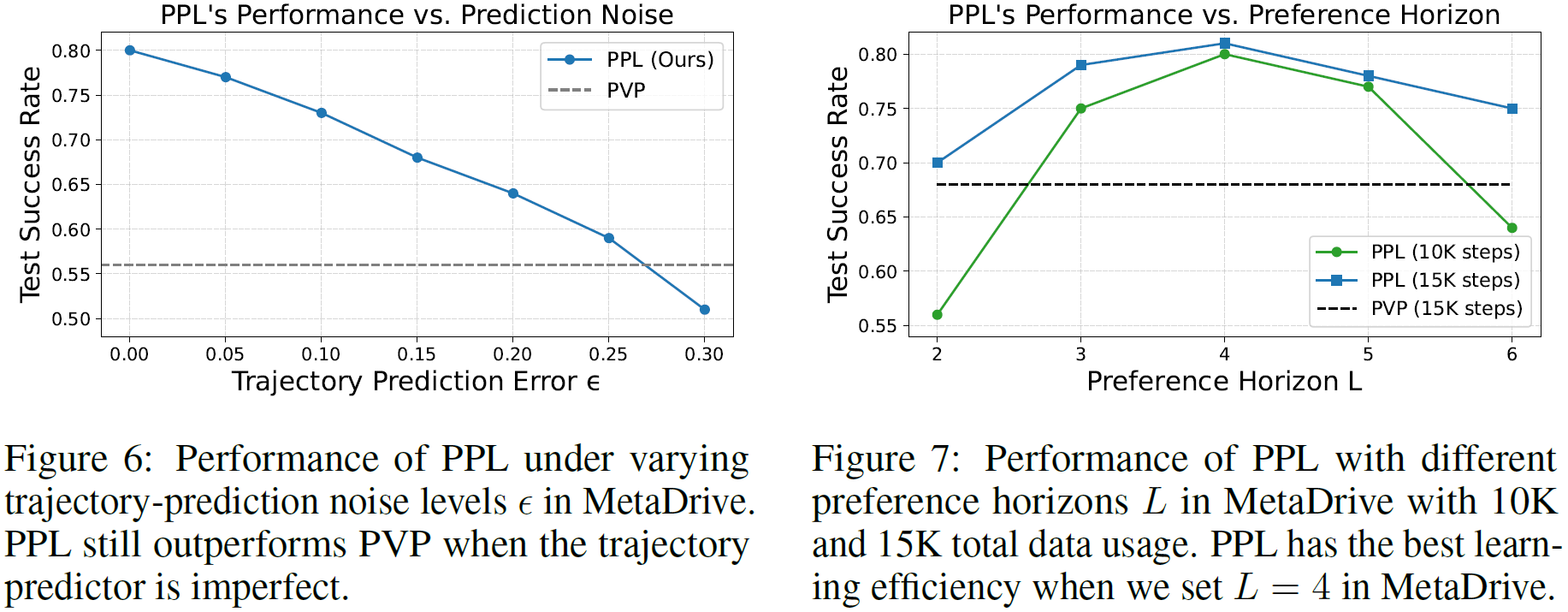
Our method PPL saves 40% human demonstrations but achieves better evaluation performance in the MetaDrive environment.
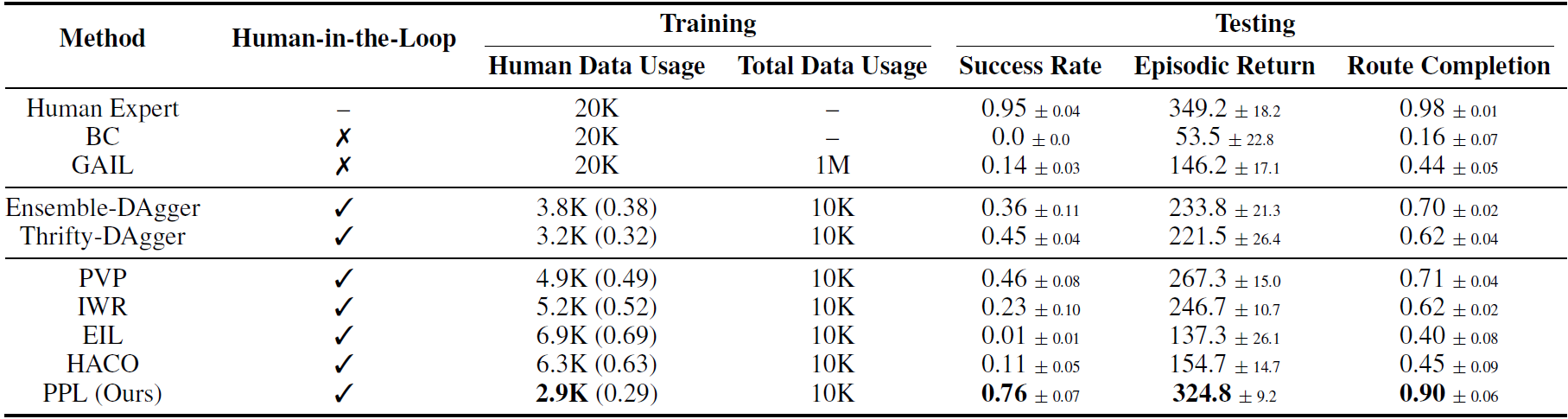
We also verify that PPL is robust to noises in the trajectory prediction model. Choosing an approximate preference horizon is essential for PPL.
Demo Video
Related Works from Us
-
Predictive Preference Learning (NeurIPS 2025): PPL is a model-based online preference learning algorithm. It predicts future failures and learn from hypotheical preference data: if expert takeover now, it might also takeover in near states if we let the agent continuously run.
-
Adaptive Intervention Mechanism (ICML 2025): AIM is a robot-gated Interactive Imitation Learning (IIL) algorithm that cuts expert takeover cost by 40%.
-
PVP for Real-world Robot Learning (ICRA 2025): We apply PVP for real-world robot learning, showing that we can train mobile robots from online human intervention and demonstration, from scratch, without reward, from raw sensors, and in 10 minutes!
-
Proxy Value Propagation (PVP) (NeurIPS 2023 Spotlight): Proxy Value Propagation (PVP) is an Interactive Imitation Learning algorithm adopts the reward-free setting and further improves learning from active human involvement. These improvements address the catastrophic forgetting and unstable behavior of the learning agent, and the difficulty in learning the sparse yet crucial human behaviors. As an PVP achieves 10x faster learning efficiency, the best user experience and safer human-robot shared control.
-
Teacher-Student Shared Control (ICLR 2023): In Teacher-Student Shared Control (TS2C), we examined the impact of using the value function as a criterion for determining when the PPO expert should intervene. TS2C makes it possible to achieve student policy that has super-teacher performance.
-
Human-AI Copilot Optimization (ICLR 2022): Building upon the methodology of EGPO, and substituting the PPO expert with a real human subject, we proposed Human-AI Copilot Optimization (HACO) and it demonstrated significant improvements in learning efficiency over traditional RL baselines.
-
Expert Guided Policy Optimization (CoRL 2021): Our research on human-in-the-loop policy learning began in 2021. The first published work is Expert Guided Policy Optimization (EGPO), where we explored how an RL agent can benefit from the intervention of a PPO expert.
Reference
Predictive Preference Learning from Human Interventions (NeurIPS 2025 Spotlight):
@article{cai2025predictive,
title={Predictive Preference Learning from Human Interventions},
author={Cai, Haoyuan and Peng, Zhenghao and Zhou, Bolei},
journal={Advances in Neural Information Processing Systems},
year={2025}
}