TL,DR: MetaVQA is a holistic benchmark for evaluating and enhancing general-purpose VLM as embodied agent.
Design Choice
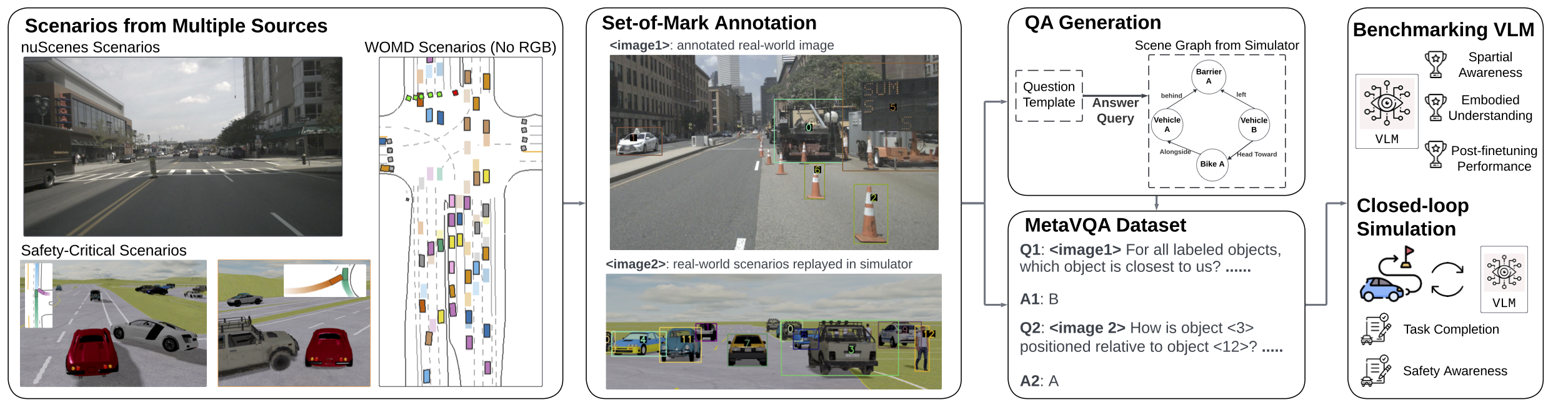
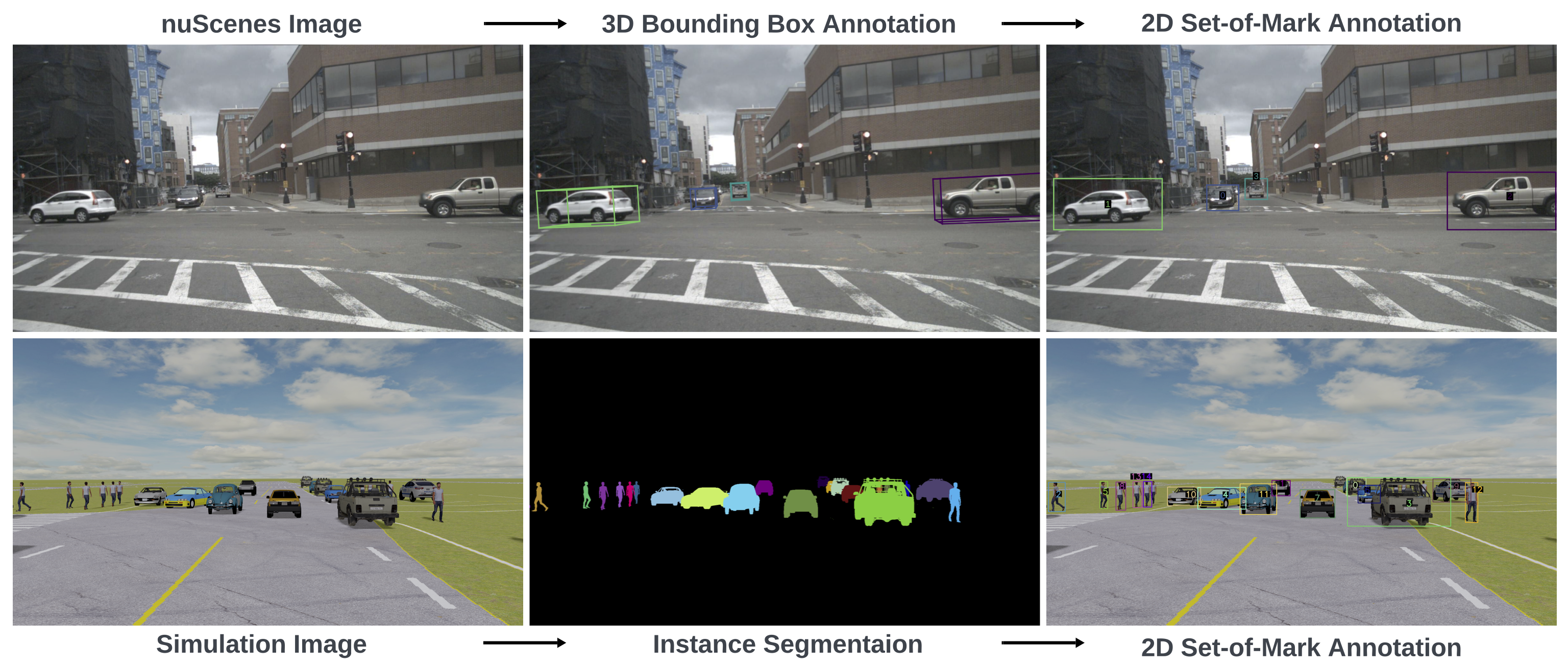
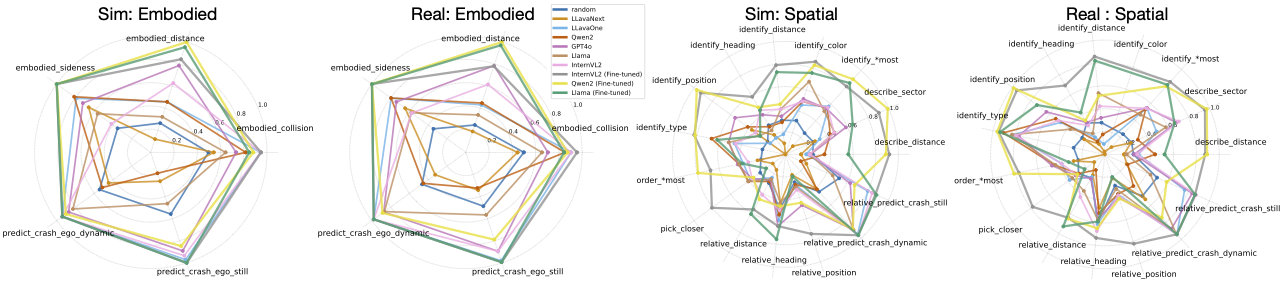
Multiple-Choice with Set-of-Marks (SoM) To effectively communicate with general-purpose vision-language models (VLMs) in visual question answering (VQA) tasks, we draw an analogy to students taking standardized tests, where clear and intuitive instructions ensure fair evaluation. Existing works rely on heterogeneous conventions, like associating pixel coordinates with image regions or using continuous versus discretized spatial information. These conventions, however, are rare in pre-training corpora dominated by human-created Internet data, making it difficult to distinguish whether poor zero-shot performance arises from a lack of scene understanding or unfamiliarity with these conventions. To address these challenges, we adopt the SoM prompting technique, which enhances visual grounding and provides unambiguous, labeled references. By formulating questions in a multiple-choice format with discretized spatial and dynamic information, we ensure fair, intuitive, and zero-shot evaluations. Our benchmark includes 30 question types that comprehensively assess spatial reasoning and embodied understanding through diverse real-world and simulated scenarios, validated further via closed-loop driving simulations.
Dataset Compositions
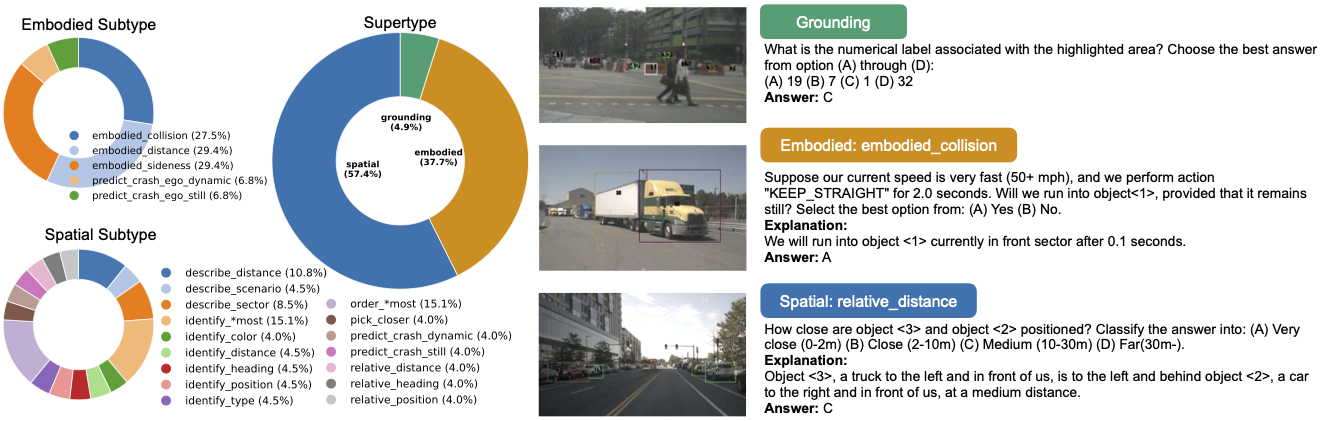
Left: Distribution of the question types. Right: Example for each question supertype.
MetaVQA Dataset consists of a large corpus of multiple-choice questions, which contains 4,305,450 questions using 442,102 annotated frames extracted from 400 nuScenes scenarios and 6,900 Waymo scenarios covering 59,682 seconds (16.5 hours) of driving log. The questions can be categorized into three supercategories: spatial questions, embodied questions, and grounding questions. The former two supercategories cover the two facets of embodied scene understanding: spatial awareness and embodied understanding, and the latter one diagnoses VLMs' capabilities to associate marked objects in the observation with textual referral.
Learned Embodied Scene Understanding
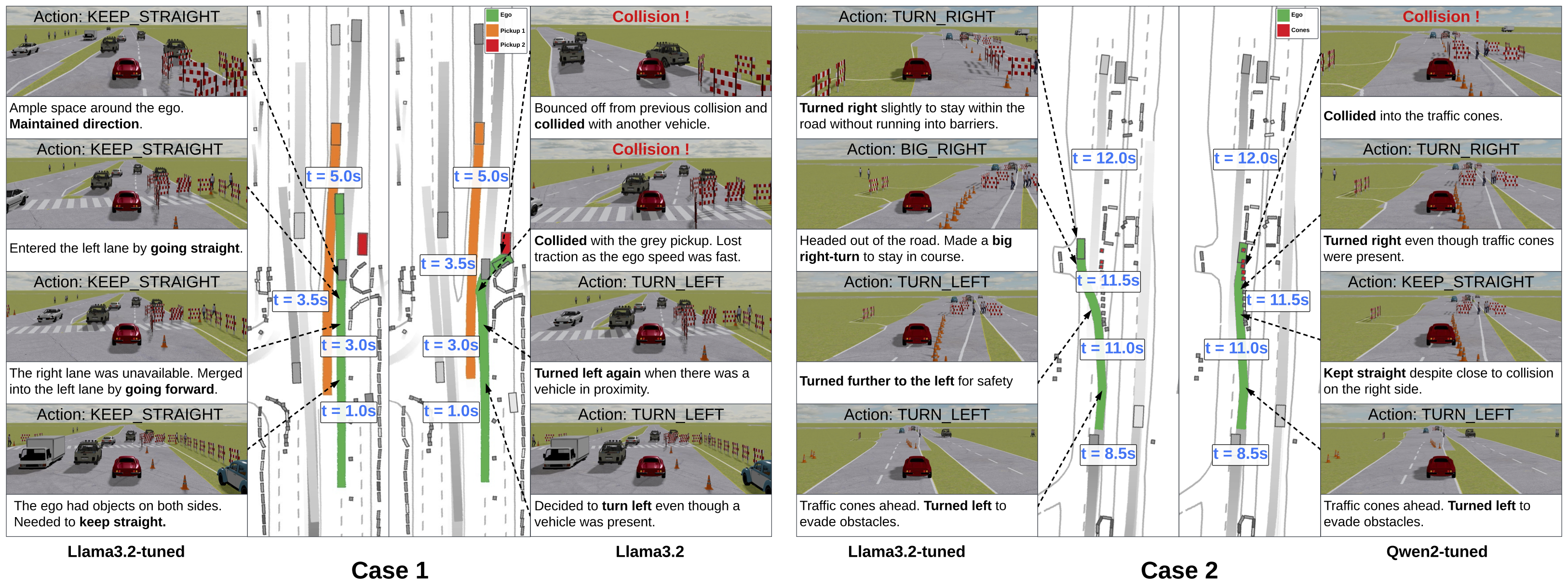
Qualitative result of closed-loop evaluation. We evaluated the performance of vision-language models in a closed-loop driving set up. Case 1 compares the performance of fine-tuned Llama3.2 (left) versus its zero-shot counterpart (right) in the same scenario. Case 2 compares the performance of fine-tuned Llama3.2 (left) versus fine-tuned Qwen2 (right). As shown, fine-tuned Llama3.2 gains elevated situational awareness and can avoid collision. It also demonstrates superior safety capability compared to its trained peers.
Improved embodied scene understanding after fine-tuning of InternVL2-8B on the withheld training set. The VLM demonstrates improved spatial understanding and embodied knowledge after learning the MetaVQA Dataset. In addition, the model attains better grounding capability.
VQA Benchmarks
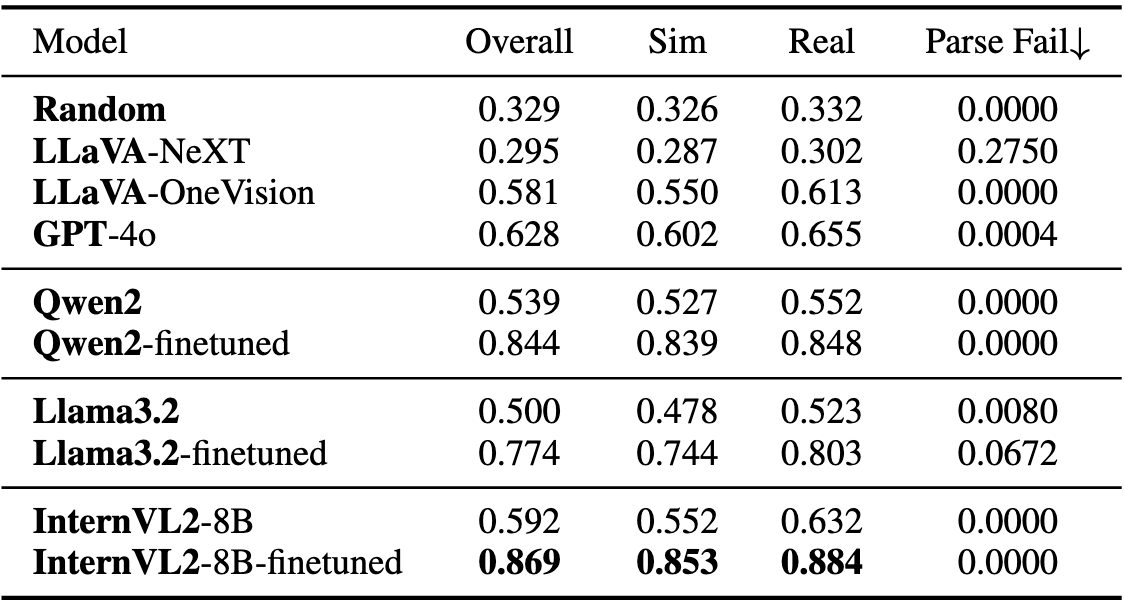
Visual question answering benchmark. Performance comparison of different models on overall, simulation-only-part, and real-only-part of the withheld test sets. The parsing failure rate is also provided. Models report consistent improvements after fine-tuning, with InternVL2-8B achieving the best performance.
Close-Loop Evaluation
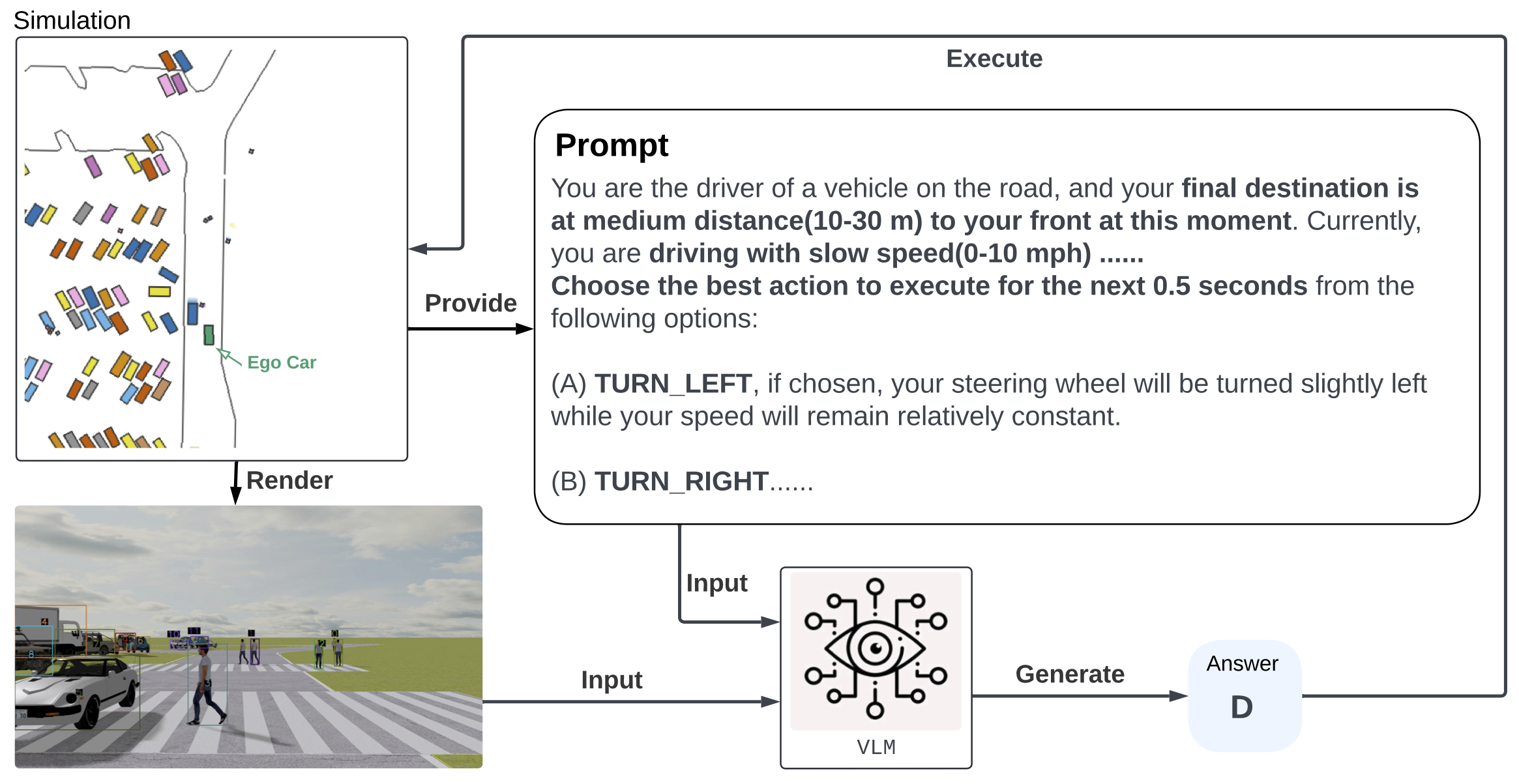
Formulation of closed-loop evaluation. At every five simulation steps (0.5 seconds wall time), the evaluated VLM is provided with annotated observations and current navigation command. The chosen action will be fed into the simulation.
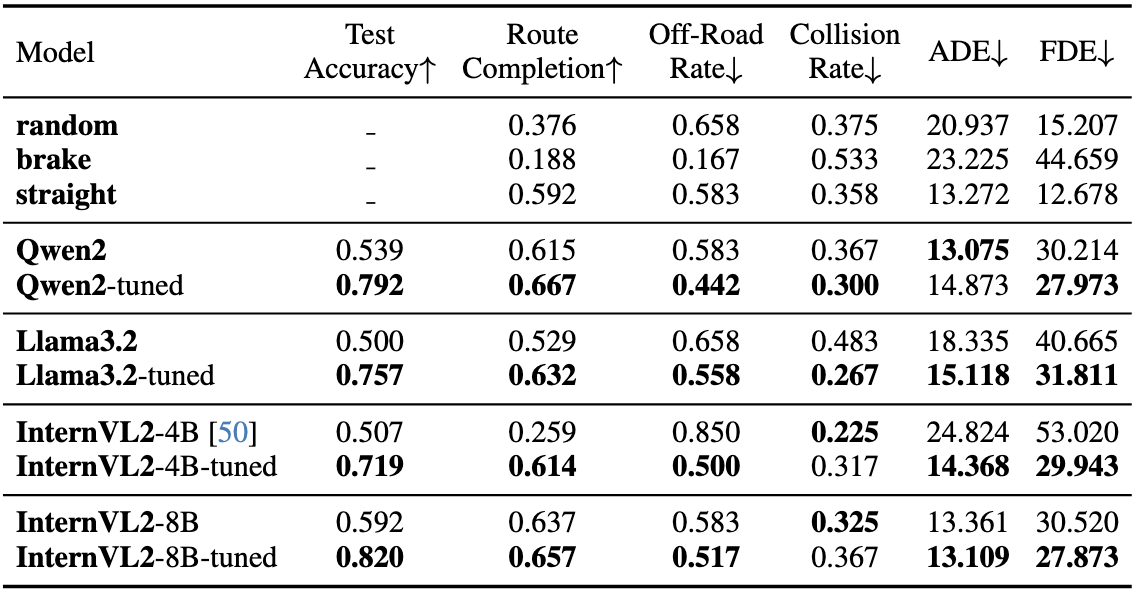
Quantitative result of closed-loop evaluation. Despite not being directly trained on the driving task, VLMs report improvements in closed-loop metrics after learning the MetaVQA Dataset, in addition to better VQA accuracy. This correlation suggests that the MetaVQA Dataset contains generalizable embodied knowledge that could be easily learned and transferred to the downstream application domain (in this case, self-driving).
Reference
@article{wang2025metavqa,
title={Embodied Scene Understanding for Vision Language Models via MetaVQA},
author={Wang, Weizhen and Duan, Chenda and Peng, Zhenghao and Liu, Yuxin and Zhou, Bolei},
journal={arXiv preprint arXiv:2501.09167},
year={2025}
}