Method Overview
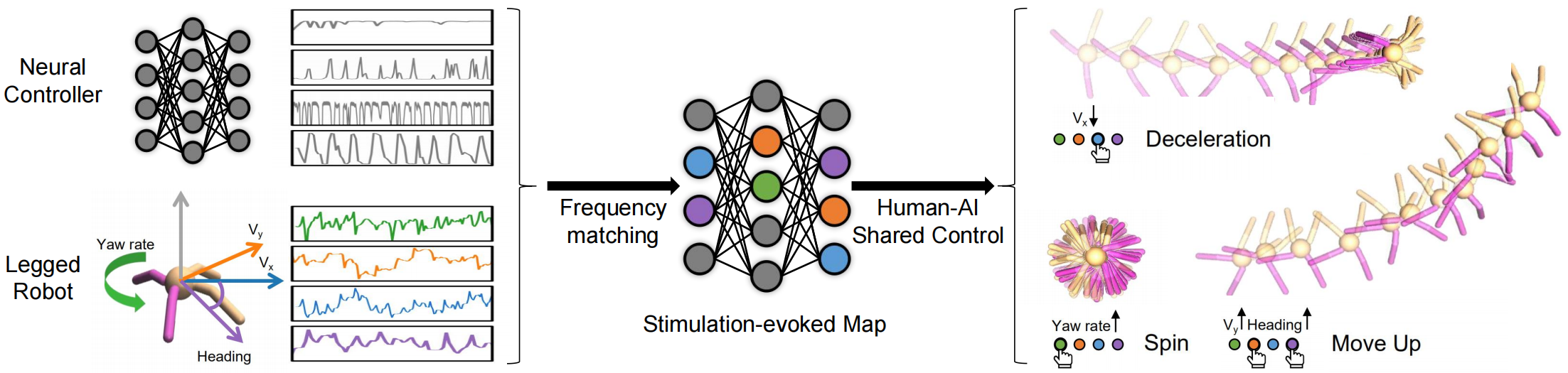
Inspired by the neuroscience approach to investigate the motor cortex in primates1, we develop a simple yet effective frequency-based approach called Policy Dissection to align the intermediate representation of the learned neural controller with the kinematic attributes of the agent behavior. Without modifying the neural controller or retraining the model, the proposed approach can convert a given RL-trained policy into a goal-conditioned policy, where specific units can be activated to evoke desired behaviors and complete goals. This, in turn, enables Human-AI shared control where human can control the trained AI and finish complex tasks.
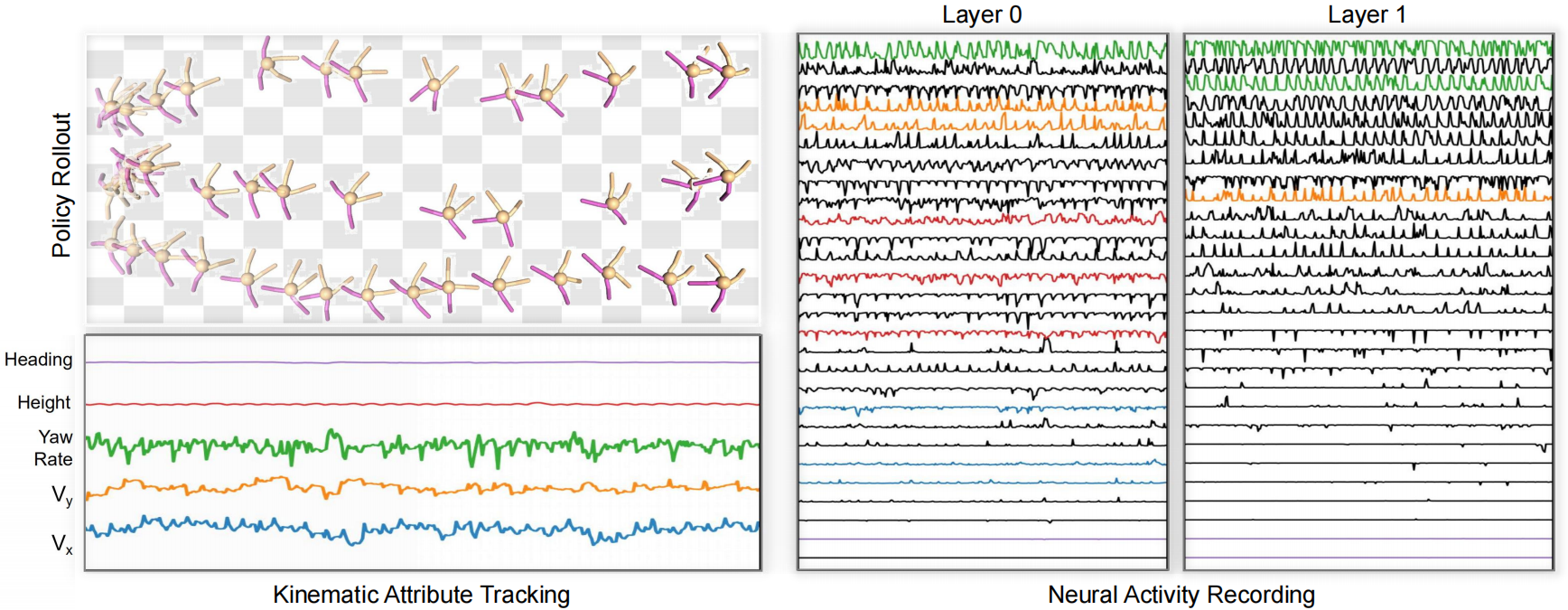
We first roll out the trained policy and record the neural activities and track kinematic attributes, like yaw and velocity. After frequency matching, kinematic attributes are associated with certain units, which are further called motor primitives. The curves of kinematic attributes and the aligned motor primitive are painted in the same colors. For clarity, we only show the result of one recorded episode and a proportion of units, and the curves of units are sorted by their amplitude.
A behavior can be described by changing a subset of kinematic attributes, which can be achieved by activating a set of corresponding motor primitives. Therefore, these movement generation building blocks, are associated with certain behaviors, yielding the stimulation-evoked map. Taking back-flip shown as an example, this behavior can be described by increasing 1. height 2. pitch and 3. knee force. Therefore, we can evoke this behavior by activating motor primitives related to the three kinematic attributes.
1. Exerting electrical stimulation on different areas of motor cortex can elicit meaningful body movements Graziano, Michael SA, et al. "The cortical control of movement revisited." Neuron 36.3 (2002): 349-362.