Learning from Active Human Involvement through Proxy Value Propagation
NeurIPS 2023 Spotlight
Zhenghao Peng 1 , Wenjie Mo 1 , Chenda Duan 1 , Quanyi Li 2 , Bolei Zhou 1
1 University of California, Los Angeles , 2 University of Edinburgh
Introduction Video
This video includes audio and is about 7 minutes.
Summary
Proxy value propagation (PVP) is a human-in-the-loop policy learning method.
- PVP is reward-free, avoiding sophisticated reward engineering.
- PVP learns from online human interventions and demonstrations, ensuring the training-time safety and benefited from corrective feedback.
In real-human experiments on various tasks and various control devices,
- PVP achieves 10x improvement in learning efficiency;
- PVP greatly boosts the agent’s training-time and test time safety performance;
- PVP makes human subjects feel better according to an user study.
Human-AI Shared Control

Among different forms of human-in-the-loop approaches, we focus on the active human involvement, where human experts oversee the exploration processes of the learning agent so that the safety of human-AI system is ensured.
As shown in the teaser videos, in training-time, the human experts can intervene and provide corrective demonstrations. We will discuss how to learn performant and human-aligned policies with the data from human-AI shared control without reward function in the following section.
Proxy Value Propagation
We learn a proxy value function along with the policy during human-AI shared control.
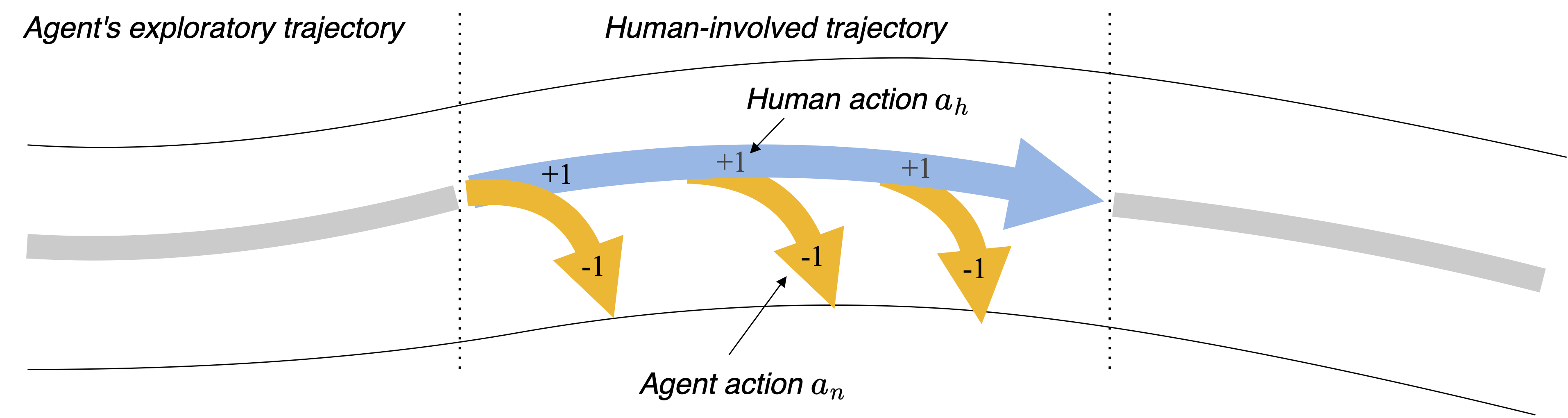
As illustrated in the figure above, we categorize the data into two partitions:
- The agent’s exploratory trajectories;
- The human-involved trajectories.
The agent’s exploratory trajectories: The state transitions \((s, a, s')\) during agent’s exploration will be stored in the Novice Buffer \(\mathcal B_n\). Note that our method is reward-free so no reward is available.
The human-involved trajectories: The actions \(a_h\) provided by the human are applied to the environment, while the agent’s actions \(a_n\) are concurrently recorded. The state transitions \((s, a_h, a_n, s')\) will be stored in the Human Buffer \(\mathcal B_h\). Again, no reward is stored.
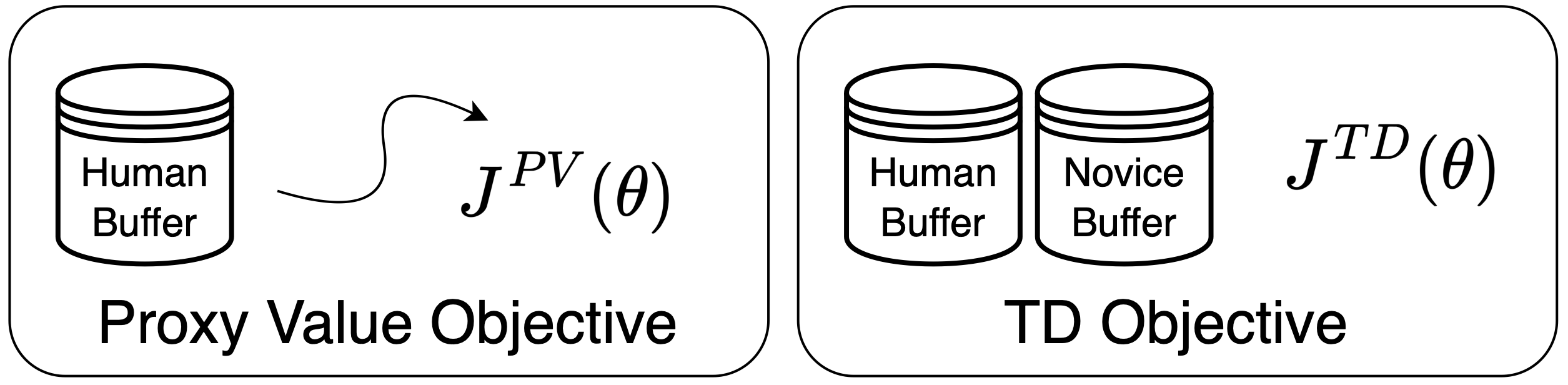
The key insight of this paper is to build a proxy value function that induces human-aligned actions and integrate the proxy value function into a value-based RL framework.
During these human-involved transitions, we optimize the proxy values to ensure the human action approximates a value close to 1, while the intervened agent actions approximate a value close to -1:

The proxy value network \(Q_\theta\) is updated with both the proxy value objective and the TD objective so that the proxy value is propagated:
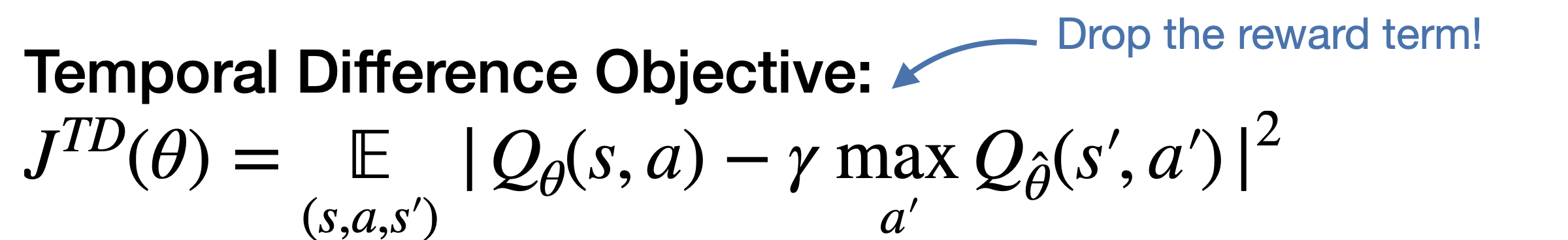
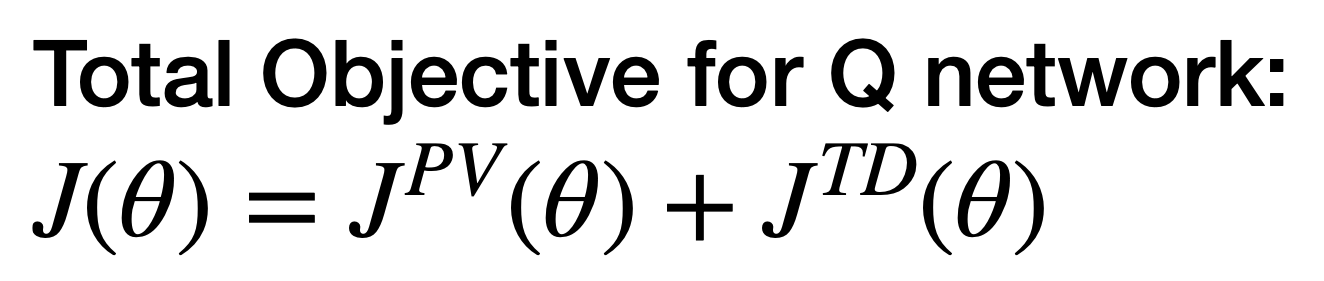
We then use value-based RL method like TD3 or DQN to optimize the policy with the proxy value function.
Experiment
Compared to the RL baselines, our method PVP achieves unprecedented learning efficiency:
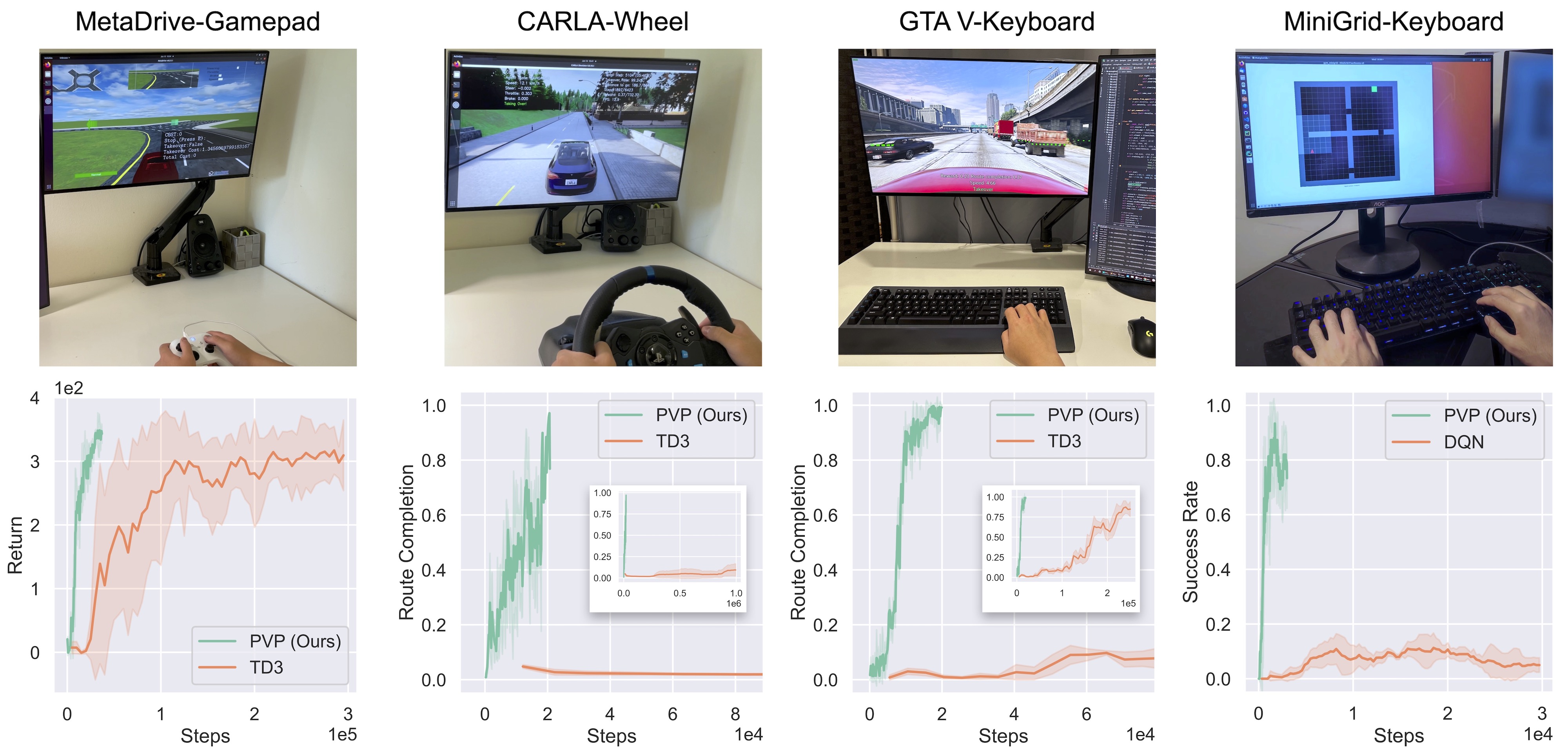
Our method PVP uses fewer demonstrations but achieves less training-time safety violation and better final performance in the MetaDrive environment.
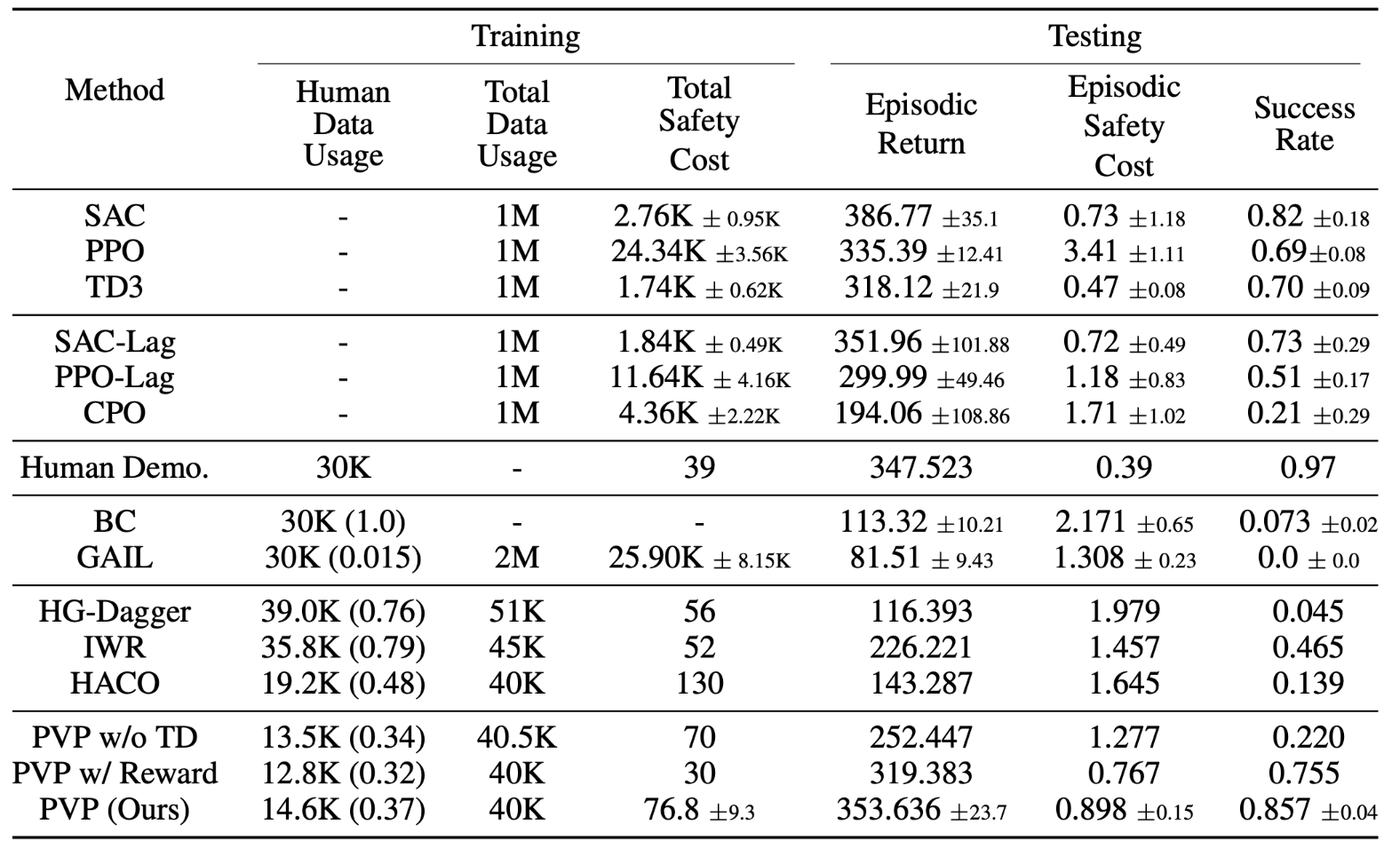
We also conduct a user study showing that PVP agents make human feels better (compliance), stronger (performance) and less stressful (stress) in shared control. It also makes human takes over less (above table).

Related Works from Us
-
Predictive Preference Learning (NeurIPS 2025): PPL is a model-based online preference learning algorithm. It predicts future failures and learn from hypotheical preference data: if expert takeover now, it might also takeover in near states if we let the agent continuously run.
-
Adaptive Intervention Mechanism (ICML 2025): AIM is a robot-gated Interactive Imitation Learning (IIL) algorithm that cuts expert takeover cost by 40%.
-
PVP for Real-world Robot Learning (ICRA 2025): We apply PVP for real-world robot learning, showing that we can train mobile robots from online human intervention and demonstration, from scratch, without reward, from raw sensors, and in 10 minutes!
-
Proxy Value Propagation (PVP) (NeurIPS 2023 Spotlight): Proxy Value Propagation (PVP) is an Interactive Imitation Learning algorithm adopts the reward-free setting and further improves learning from active human involvement. These improvements address the catastrophic forgetting and unstable behavior of the learning agent, and the difficulty in learning the sparse yet crucial human behaviors. As an PVP achieves 10x faster learning efficiency, the best user experience and safer human-robot shared control.
-
Teacher-Student Shared Control (ICLR 2023): In Teacher-Student Shared Control (TS2C), we examined the impact of using the value function as a criterion for determining when the PPO expert should intervene. TS2C makes it possible to achieve student policy that has super-teacher performance.
-
Human-AI Copilot Optimization (ICLR 2022): Building upon the methodology of EGPO, and substituting the PPO expert with a real human subject, we proposed Human-AI Copilot Optimization (HACO) and it demonstrated significant improvements in learning efficiency over traditional RL baselines.
-
Expert Guided Policy Optimization (CoRL 2021): Our research on human-in-the-loop policy learning began in 2021. The first published work is Expert Guided Policy Optimization (EGPO), where we explored how an RL agent can benefit from the intervention of a PPO expert.
Reference
Proxy Value Propagation (NeurIPS 2023 Spotlight):
@article{peng2023learning,
title={Learning from Active Human Involvement through Proxy Value Propagation},
author={Peng, Zhenghao and Mo, Wenjie and Duan, Chenda and Li, Quanyi and Zhou, Bolei},
journal={Advances in Neural Information Processing Systems},
year={2023}
}
Acknowledgement: This work was supported by the National Science Foundation under Grant No. 2235012. The human experiment in this study is approved through the IRB#23-000116 at UCLA.